
Me, Myself and AI: 5 Days, 2 Models, 200M Tokens
Some thoughts after using Claude 4.5 and GPT-5 Codex across Cursor and Augment Code

The Experiment That Changed Everything
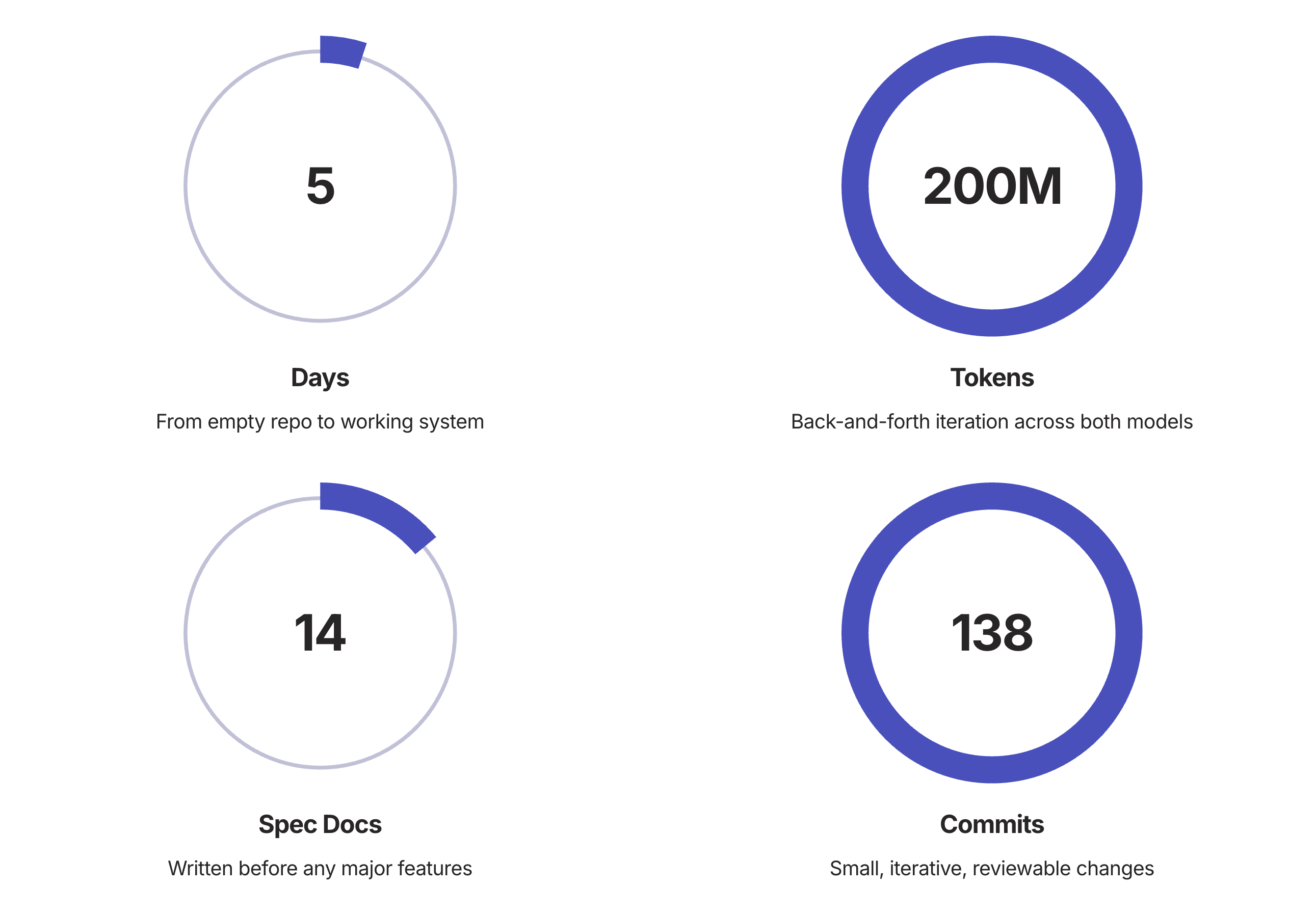
I just spent 5 days building with AI coding assistants—not just tinkering around the edges, but going from an empty repository to a fully working platform. This was my first time truly partnering with AI to ship something real, and it fundamentally changed how I think about software development.
The setup was deliberately designed to leverage the strengths of multiple models while keeping them accountable to each other. Two cutting-edge models, two powerful coding tools, and a workflow that forced them to challenge each other's assumptions. What emerged was faster than I expected, more robust than either model alone could achieve, and full of insights about how AI-assisted development actually works in practice.
This isn't a story about AI replacing developers. It's about amplifying what we can build when we architect the right collaboration between human judgment and machine capability.
5 Days, Concept to working system | 200M Tokens, Iterative conversations | 138 Commits, Small, focused changes
The Multi-Model Workflow
The key to making this work wasn't just using AI—it was using AI strategically. Instead of relying on a single model, I built a workflow that put different models in different roles, then forced them to review each other's work.
Tool Strengths: Finding the Right Model for Each Job
Performance Note: Augment Code sometimes slowed down dramatically, especially running the full stack locally in Docker. Worth investigating the memory footprint of VSCode with Augment vs Cursor. Cursor seemed to maintain speed even as the repo and context grew larger.
Patterns That Actually Worked
By the Numbers: What 200M Tokens Actually Built
Two Coding Tools Working in Tandem
Cursor and Augment Code each brought different strengths to the table. Rather than picking one, I used both strategically—Cursor for its consistent performance and speed, Augment for its deep debugging capabilities and spec adherence.
The ability to switch between tools meant I could choose the right environment for each type of task, making the overall workflow more efficient.

The (Maybe Over-Engineered) Stack
I'll be honest—I might have gone overboard with the architecture. But the AI models handled it surprisingly well, and the comprehensive specs kept everything aligned with the original design.
Could I have simplified this? Probably. But the models handled the complexity fairly well, and the specs helped A LOT to keep everything aligned with what I designed.
What I Learned About AI-Assisted Development
Engineering Still Matters
The tools are incredibly powerful, but you absolutely need structure. AI doesn't replace architectural thinking—it amplifies it. You need to know when the AI is wrong, understand the tradeoffs between different approaches, and maintain a clear vision of what you're building.
The moments when models disagreed were often the most valuable, because they forced me to dig deeper and truly understand the implications of each choice.
Architecture First
AI can implement your vision, but you need to provide that vision. The 14 spec documents weren't busywork—they were the foundation that made everything else possible.
Review Everything
Never blindly accept AI-generated code. The review loop where one model critiques another's work caught subtle bugs and improved code quality significantly.
Speed Matters
Claude 4.5's speed improvement over Claude 4 wasn't just a nice-to-have—it fundamentally changed the workflow. Faster iteration meant more experiments, quicker fixes, and better end results.
The Honest Truth: Challenges and Trade-offs
Bottom Line: Me, Myself, and AI Did a Great Job
With the right workflow, you can move incredibly fast. Five days from concept to working system isn't just impressive—it's a glimpse of what software development looks like when humans and AI collaborate effectively.
The key insights that made this work:
- Specs keep models honest and aligned
- Multiple models catch more issues than either alone
- Claude 4.5's speed is a huge improvement
- Engineering judgment is more important than ever
- The right tools for the right tasks matter
What's Next?
I'm iterating on agent management patterns as I prepare this for production. The core system works, but there's refinement needed—simplifying where possible, optimizing for performance, and documenting the patterns that emerged from this experiment.
The future of development isn't AI replacing developers. It's developers who know how to orchestrate AI effectively replacing those who don't. This experiment proved that with structure, multiple models, and thoughtful workflow design, the productivity gains are real and substantial.
Overall... me, myself, and AI did a great job. And we're just getting started.